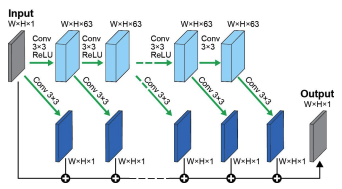
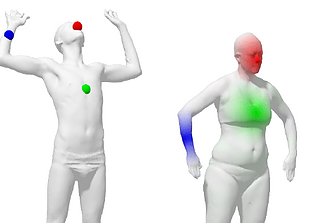
Tal Remez, Ph.D.

I am an AI researcher with a PhD in machine learning, specializing in the development of large-scale foundation models and innovative architectures like world models. My expertise spans multi-modal large language models (LLMs) encompassing video, audio, and textual data, as well as core areas like optimization, visual perception, and computational photography.
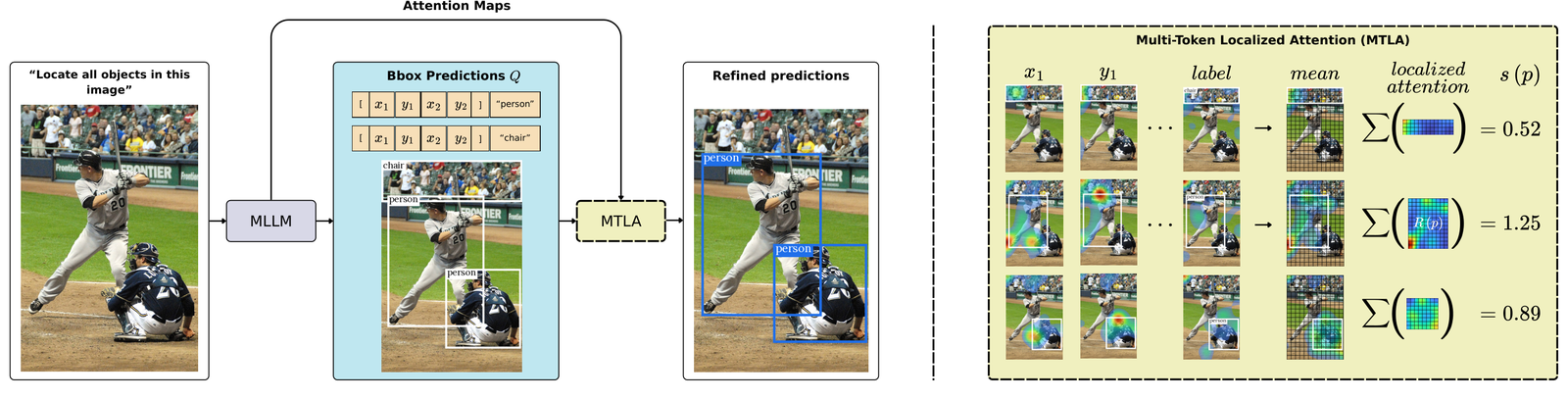
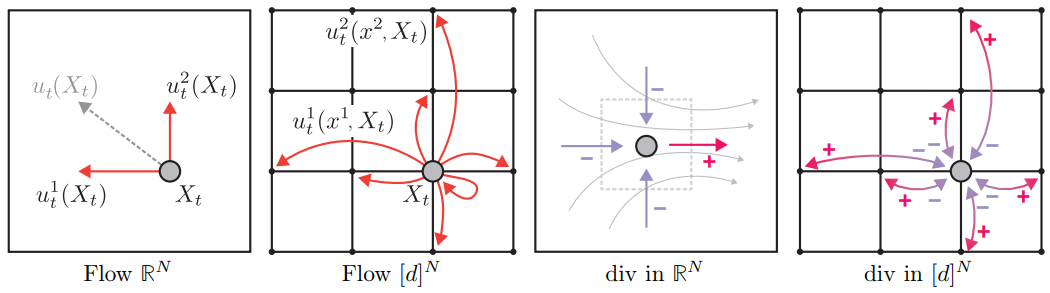
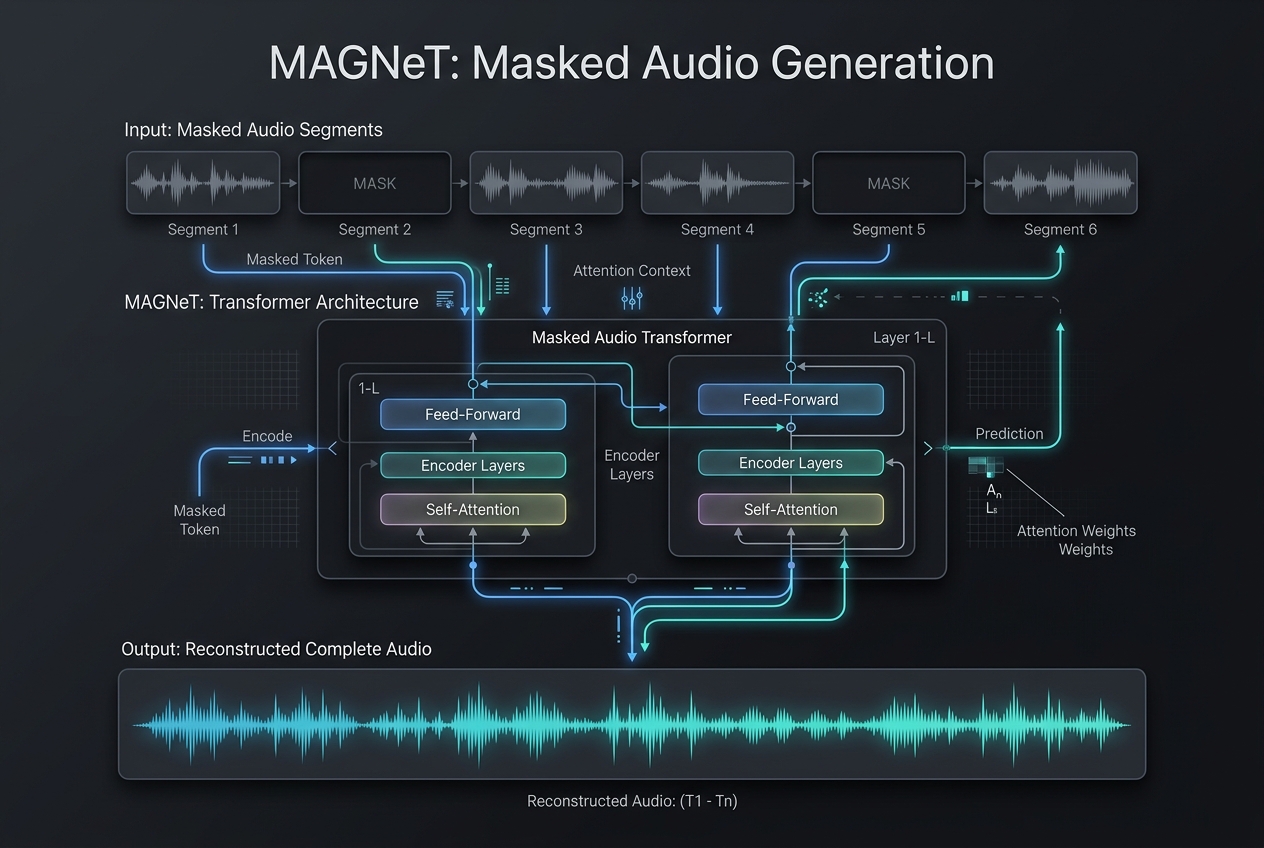
My latest work at Amazon and FAIR has centered on pushing the boundaries of these models, including leading a project on large-scale multi-modal foundation models for sport understanding and developing a "Code World Model." This work includes high-impact applications of multi-modal LLMs in audio/music generation, text/code generation, and advanced research into techniques like flow matching and discrete flow matching for tasks such as text continuation and chain-of-thought reasoning.
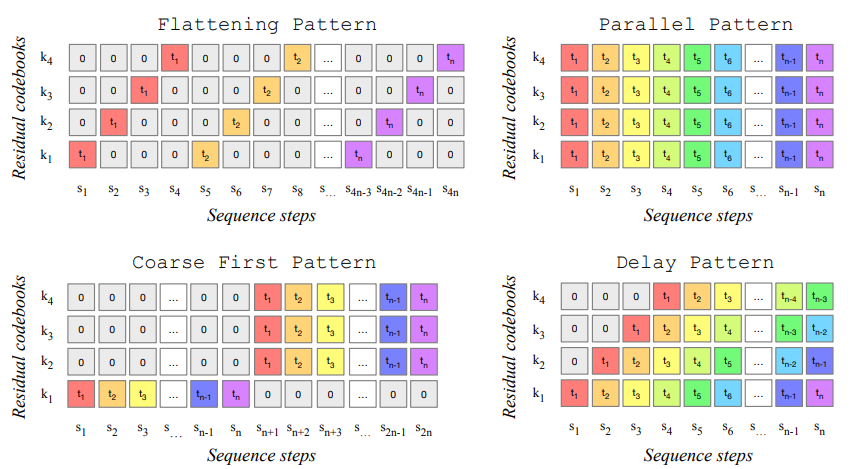
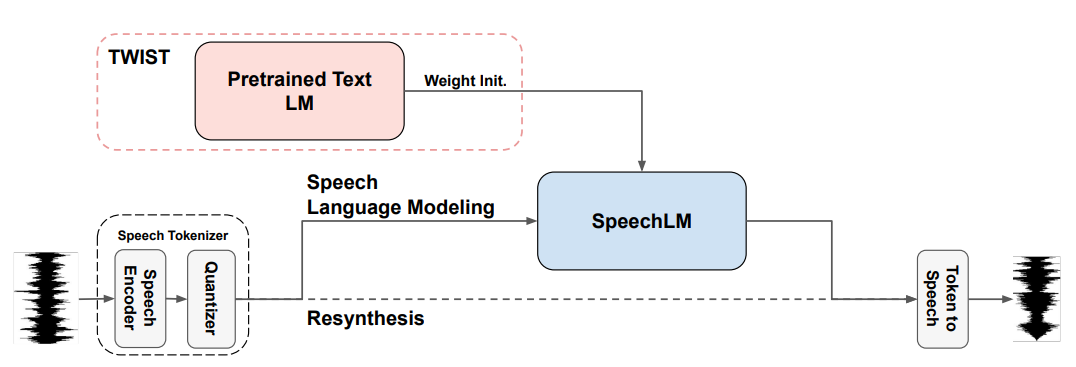
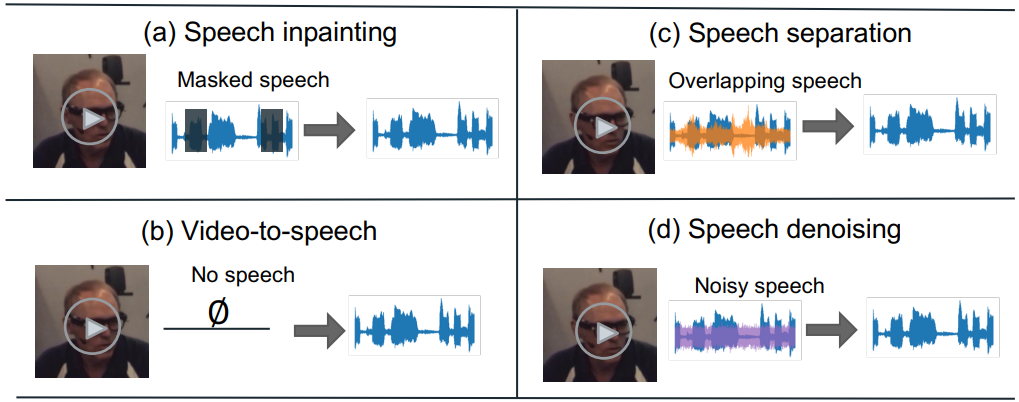
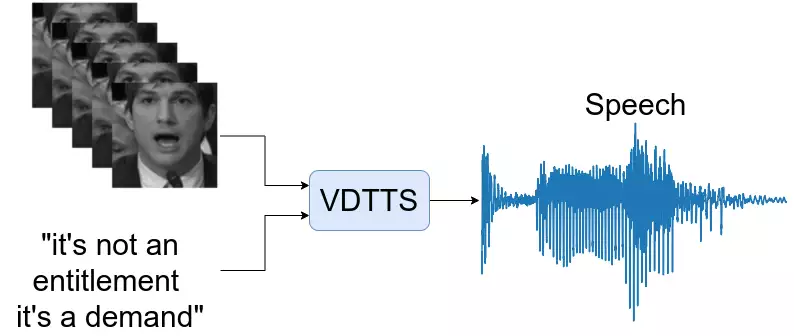
Publications